Structure of Codebase
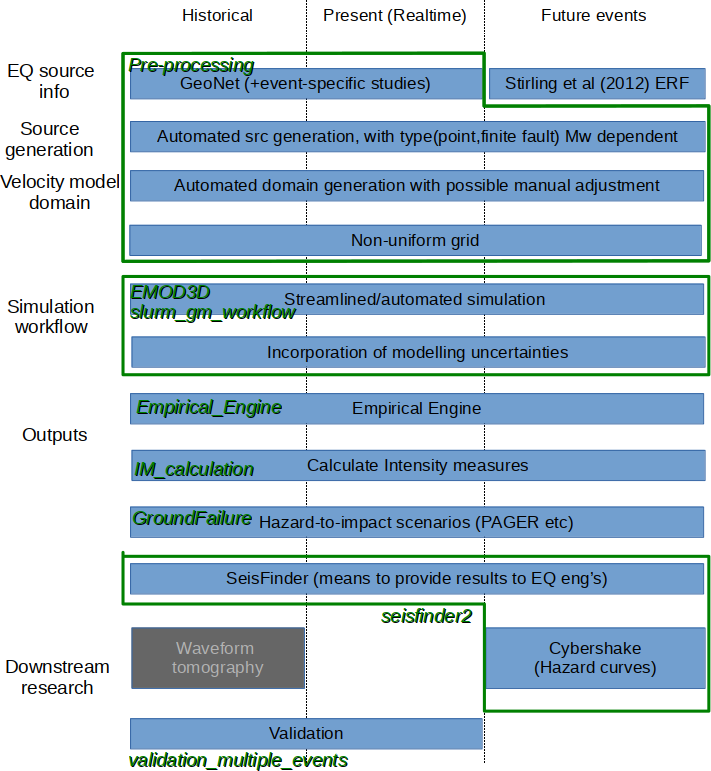
(from SW Codebase 2019 page : qcore, visualisation and GMSimViz are not listed.
This page is somewhat outdated, but contains some useful background)
Repository Specific Improvements
| Repo | Improvement | Note |
|---|---|---|
| https://github.com/ucgmsim/slurm_gm_workflow | Outstanding issues
Improvements
| |
Remove unneeded code/functions More coherent structure with related functions kept in the same file Consistent comment styles using doctoring and API doc Expand automated unit test coverage (less than 10%) (lat.lon).csv → grid.xml currently not used. Plan for PAGER? | ||
Better estimation for model generation Repo restructure : GMSim_model, NonUniformGrid and archive unused legacy code Incorporate model generation into management DB (See slurm_gm_workflow) Automated testing for model generation NonUniformGrid code has minor issues (but low priority, run yearly) | ||
Regression tests (after scientific validation) GM selection Login and user management Missing ver.1 features:
| ||
Clean up Python 3 Refactor plot_stations.py | ||
Integrate into hazard workflow (replacing OpenPSHA, no new functionality, but can streamline empdb creation) | ||
| Clean up | ||
Mixed effect regression workflow to be version-controlled Add automation Improve the code quality | ||
| https://github.com/ucgmsim/GMSimViz | Specifying regions of interest | |
| Decide if seisfinder2 needs this | ||
Include just .000 and .090 for geom only (33% speed up) Calculate RTVZ and RX Replace Cython spectra with better Python code | ||
Velocity_Model | - | |
| - |
Common Improvements
- Template for README : Amalgamate README, Codebase wiki page and repo maturity page, and put everything in README.
- Python 3 and coding & comment style
- Automated testing and Continuous integration
Stable Release
A repository that satisfies the following criteria will have an official stable release.
- All the planned functionalities have been developed and tested
- Codebase has been cleaned up
- Good comments & documentation (README)
- Automated testing coverage over 80%
Ideally, we can have the package installed via "pip" command:
pip install qcore
The repositories we should aim to produce stable releases are (ordered by impact/risk analysis)
- IM_calculation
- Pre-processing
- Qcore
- Slurm_gm_workflow
Moving Forward: Mid April - End of June
- Stable release of IM_calc and Pre-processing repos : Initially small team of 2~3 piloting, polishing up the process
- IM_Calc:
- Clean up
- Finish automated testing
- Comment style,
- README.md
- Release
- Pre-processing:
- Better estimation,
- Split the repo : Model_gen, Grid_gen
- Clean up
- Automated testing
- Comment style
- README.md
- Release
- IM_Calc:
- Slurm_gm_workflow & Qcore restructuring
- Slurm_gm_workflow:
- Restructure, split the repo. make all .yaml compliant
- Remove/update legacy code
- Integrate Pre-processing into automated workflow
- Logging
- Automated verification
- Estimation performance
- Visualisation
- Error handling
- Realisation name change
- Qcore
- Restructure
- Clean ujp
- Comments in Numpy style
- Increase automated unit test coverage
- API doc
- README
- Slurm_gm_workflow:
- SeisFinder2: Feature completion (3months time frame)
- Integration of GM selection
- Verification and regression testing etc.
- Lite version(?)
- README template : Example https://gist.github.com/PurpleBooth/109311bb0361f32d87a2 : TODO, Changelog etc.
- Standard for comment and API doc :NumPy vs Google
- Cybershake
- Include subduction
- Check the performance of new VM and run 1 cycle of Cybershake
- HF changes (inc. path duration)
- Deagg and determines more relevant faults, rerun Cybershake with less fault, higher res.
3 Comments
Daniel Lagrava
Some random thoughts from my part here. Feel free to remove if clutter.
Sung Bae
Jason Motha
With regard to versioning the whole system. I think that specifying dependant versions of repositories in the setup.py should allow you to "time-travel" effectively as you know that this version is compatible with this version at this point in time.
slurm workflow seems to have a lot of moving parts. It's been a huge focus for us in development this year in pair with our efforts on automation.