Summaries
Reading from CSVs took 6.5sec for each set of (loc, IM type)
Reading from IMDB also takes 6.5sec for each set of (loc, IM type) for adding the data to the column. BUT if user varies IM level, it only takes 1 sec.
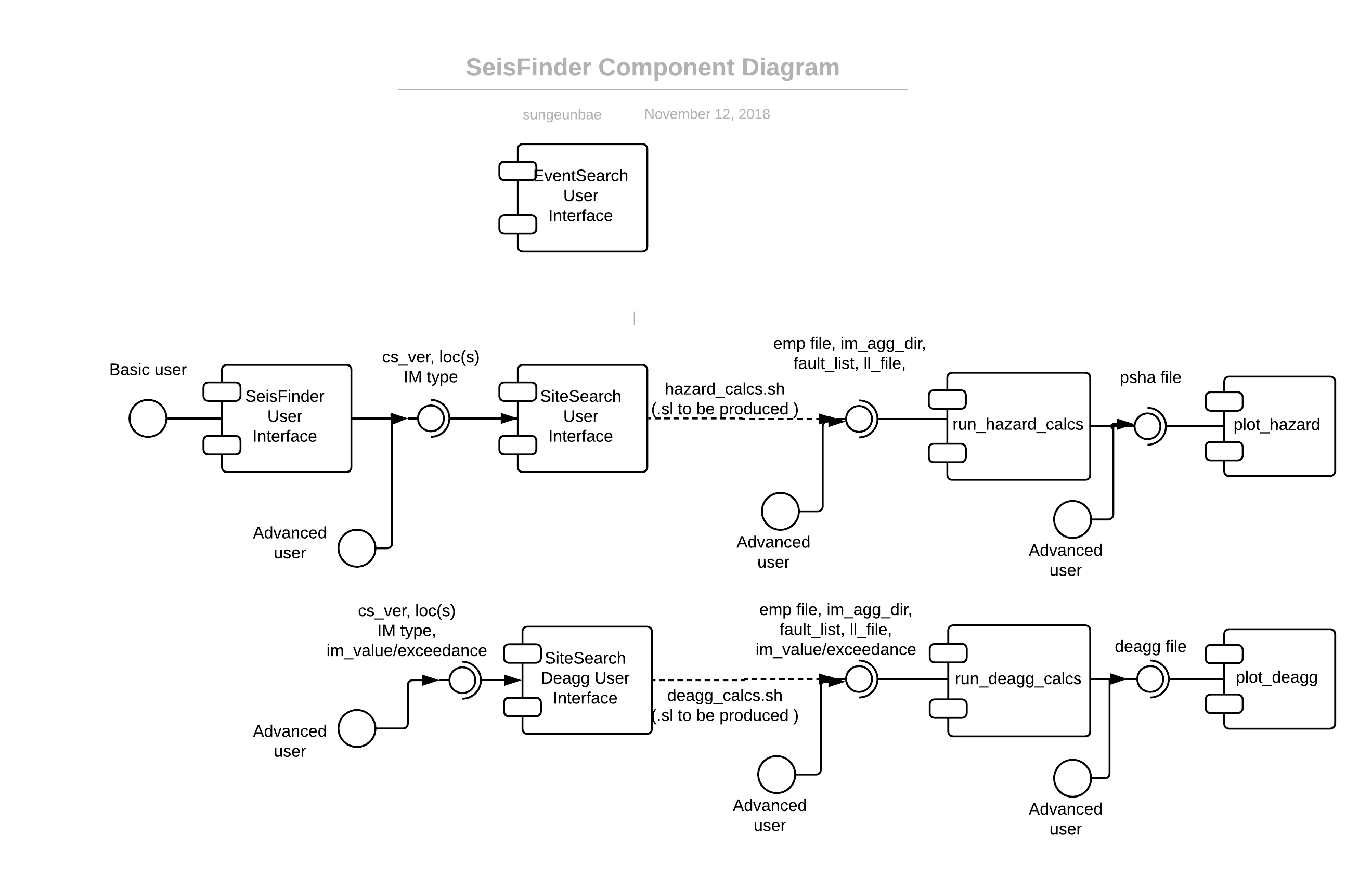
Calculation of Hazard and Deagg is streamlined, and it submits the auto-generated slurm scripts.
Story / Deliverable
When calculating deagg with IM type, location and cs_ver, varying IM_level or exceedance should not force the program to re-read raw IM agg data and process them.
When calculating GM selection, user should be able to use the same set of parameters as deagg calculation
Streamline hazard/deagg calculation steps
Tasks/Progress
| Who | Status | Deliverables | |||
|---|---|---|---|---|---|
| (1) | Precompute SQLite db for all IM_agg data | 1 day | Viktor | Done | |
| (2) | Develop an API that outputs all IMs in a numpy array for given IM type, station name | 1 day | Viktor | Done | |
| (3) | Update setup process to do step (1) automatically. | 1 day | Sung | Done | |
| (4) | Fix hazard to use the API from (2) | 1 day | Sung | Done | |
| (5) | Fix deagg to use the API from (2) | 1 day | Sung | Done | |
| (6) | Write site_search_gm_sel.py that mimics the interface of site_search_deagg.py | 1 day | Viktor | Done(to be revisited) | |
| (7) | Automatically generate sl scripts and submit for hazard/deagg calc | 2 days | Sung | Done |
Known Issues / To Dos
- Fault screening based on user specified loc vs. simulation domain is no longer necessary as the API from (2) does all the filtering already.